DeeperForensics-1.0: A Large-Scale Dataset for Real-World Face Forgery Detection
|
Nanyang Technological University
|
SenseTime Research
|
|
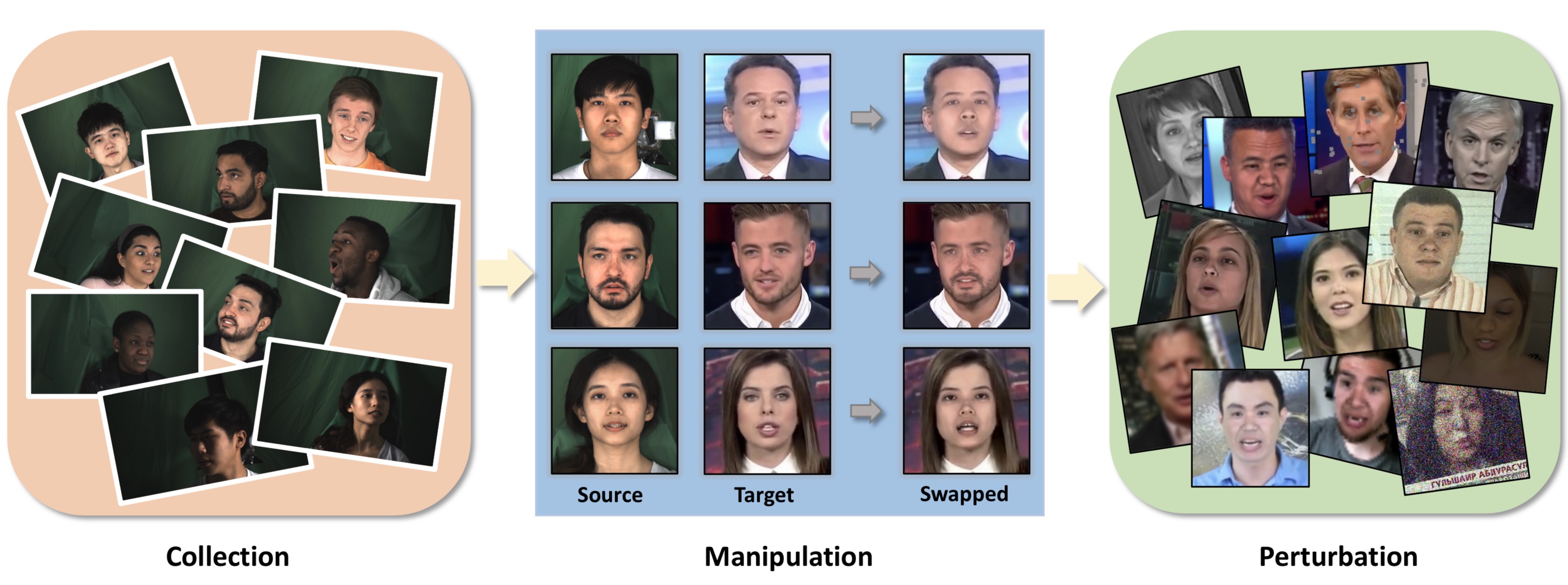
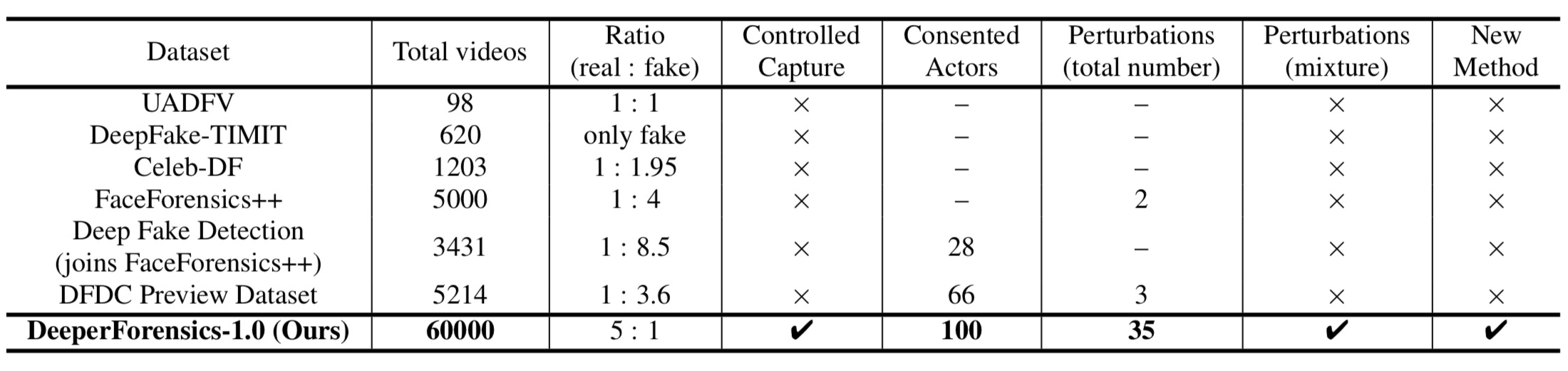
We present our on-going effort of constructing a large-scale benchmark for face forgery detection. The first version of this benchmark, DeeperForensics-1.0, represents the largest face forgery detection dataset by far, with 60,000 videos constituted by a total of 17.6 million frames, 10 times larger than existing datasets of the same kind. Extensive real-world perturbations are applied to obtain a more challenging benchmark of larger scale and higher diversity. All source videos in DeeperForensics-1.0 are carefully collected, and fake videos are generated by a newly proposed end-to-end face swapping framework. The quality of generated videos outperforms those in existing datasets, validated by user studies. The benchmark features a hidden test set, which contains manipulated videos achieving high deceptive scores in human evaluations. We further contribute a comprehensive study that evaluates five representative detection baselines and make a thorough analysis of different settings.
Paper
 |
DeeperForensics-1.0: A Large-Scale Dataset for Real-World Face Forgery Detection
Liming Jiang, Ren Li, Wayne Wu, Chen Qian, Chen Change Loy
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020
|
Challenge Report
 |
DeeperForensics Challenge 2020 on Real-World Face Forgery Detection: Methods and Results
Liming Jiang, Zhengkui Guo, Wayne Wu, Zhaoyang Liu, Ziwei Liu, Chen Change Loy, et al.
arXiv preprint, 2021
|
Book Chapter
 |
DeepFakes Detection: the DeeperForensics Dataset and Challenge
Liming Jiang, Wayne Wu, Chen Qian, Chen Change Loy
Digital Face Manipulation and Detection - From DeepFakes to Morphing Attacks, Springer, 2022
|
Comparison
|
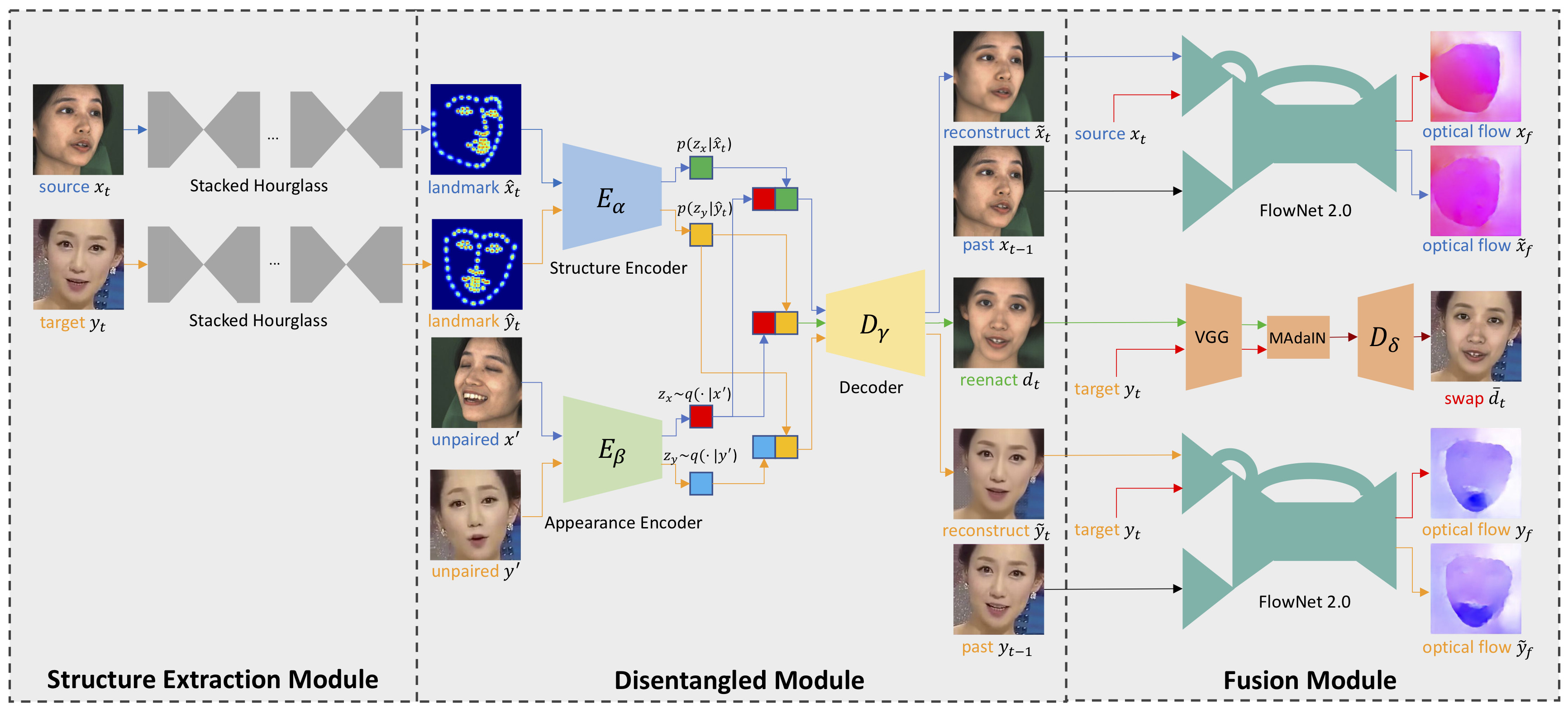
Method (DF-VAE)
|
We also propose a new learning-based many-to-many face swapping method, DeepFake Variational Auto-Encoder (DF-VAE). DF-VAE improves scalability, style matching, and temporal continuity to ensure face swapping quality. In training, we reconstruct the source and target faces in blue and orange arrows, respectively, by extracting landmarks and constructing an unpaired sample as the condition. Optical flow differences are minimized after reconstruction to improve temporal continuity. In inference, we swap the latent codes and get the reenacted face in green arrows. Subsequent MAdaIN module fuses the reenacted face and the original background resulting in the swapped face.
Visualizations

|

|
Extensive Data Collection
Several Face Manipulation Results
Many-to-Many (Three-to-Three) Face Swapping by a Single Model
Diverse Perturbations in Real World
Acknowledgments
This work is supported by the SenseTime-NTU Collaboration Project, Singapore MOE AcRF Tier 1 (2018-T1-002-056), NTU SUG, and NTU NAP. We gratefully acknowledge the exceptional help from Hao Zhu and Keqiang Sun for their contribution on source data collection and coordination.
|